什么是布隆过滤器
如果想知道什么是布隆过滤器的介绍,一定能解决您的问题的,一起来了解吧!
布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,用于判断一个元素是否在一个集合中。
它基于位数组和多个哈希函数的原理,可以高效地进行元素的查询,而且占用的空间相对较小,如下图所示:
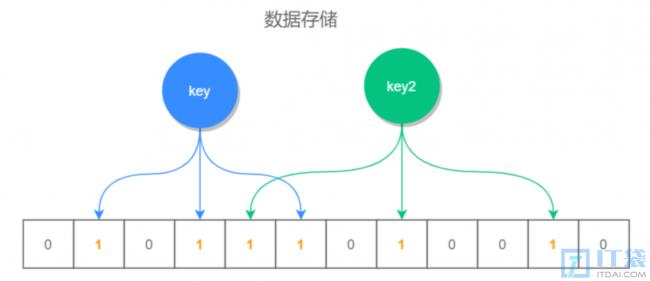

根据 key 值计算出它的存储位置,然后将此位置标识全部标识为 1(未存放数据的位置全部为 0),查询时也是查询对应的位置是否全部为 1,如果全部为 1,则说明数据是可能存在的,否则一定不存在。
也就是说,如果布隆过滤器说一个元素不在集合中,那么它一定不在这个集合中;但如果它说一个元素在集合中,则有可能是不存在的(存在误差)。
1.布隆执行过程
布隆过滤器的具体执行步骤如下:
- 在 Redis 中创建一个位数组,用于存储布隆过滤器的位向量。
- 初始化多个哈希函数,并将每个哈希函数的计算结果对应的位数组位置设置为 1。
- 添加元素到布隆过滤器时,对元素进行多次哈希计算,并将对应的位数组位置设置为 1。
- 查询元素是否存在时,对元素进行多次哈希计算,并检查对应的位数组位置是否都为 1。
2.布隆使用场景
布隆过滤器的主要使用场景有以下几个:
- 大数据量去重:可以用布隆过滤器来进行数据去重,判断一个数据是否已经存在,避免重复插入。
- 缓存穿透:可以用布隆过滤器来过滤掉恶意请求或请求不存在的数据,避免对后端存储的频繁访问。
- 网络爬虫的 URL 去重:可以用布隆过滤器来判断 URL 是否已经被爬取,避免重复爬取。
3.如何实现布隆过滤器?
在 Redis 中不能直接使用布隆过滤器,但我们可以通过 Redis 4.0 版本之后提供的 modules (扩展模块) 的方式引入,它的实现步骤如下。
① 打包RedisBloom插件
git clone https://github.com/RedisLabsModules/redisbloom.gitcd redisbloommake # 编译redisbloom编译正常执行完,会在根目录生成一个 redisbloom.so 文件。
② 启用RedisBloom插件
重新启动 Redis 服务,并指定启动 RedisBloom 插件,具体命令如下:、
redis-server redis.conf --loadmodule ./src/modules/RedisBloom-master/redisbloom.so③ 创建布隆过滤器
创建一个布隆过滤器,并设置期望插入的元素数量和误差率,在 Redis 客户端中输入以下命令:
BF.RESERVE my_bloom_filter 0.01 100000如何实现?,什么是布隆过滤器。小编来告诉你更多相关信息。
什么是布隆过滤器
④ 添加元素到布隆过滤器
在 Redis 客户端中输入以下命令:
BF.ADD my_bloom_filter leige⑤ 检查元素是否存在
在 Redis 客户端中输入以下命令:
BF.EXISTS my_bloom_filter leige上面为您介绍的什么是布隆过滤器 如何实现?的全面介绍了,希望给网的网友们带来一些相关知识。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。如发现本站有涉嫌抄袭侵权/违法违规的内容,请发送邮件至 5733401@qq.com 举报,一经查实,本站将立刻删除。本文链接:https://fajihao.com/i/269991.html